Notes from aaDH Digital Humanities Australasia Conference
June 20-23, 2016
Hobart, Tasmania, Australia
Conference abstracts PDF
Twitter #DHA2016

The following are my notes from the Digital Humanities Australasia conference (June 20-23, 2016), the third conference of the Australasian Association for Digital Humanities (aaDH), held in Hobart, Tasmania, Australia). These are not comprehensive notes but rather what caught my attention in relation to my continually developing understanding of DH.
Although it is interesting to see the wide spectrum of presentations at DH conferences—from easily understandable/accessible ideas all the way to more technical descriptions of programs and methodologies—the highly technical ones seem to lose a fair portion of the often interdisciplinary DH audiences, which can include more traditional humanists, the GLAM sector, and computer scientists. Pitching to the right level may not be a resolvable issue because of this, but it is probably safer to assume that everyone isn’t familiar with programming complexities. There is a sense that people are not following when the Twitter feed dries up and no one asks any questions. Something else that was mentioned was making sure that Twitter handles are in the program. I have endeavored to include handles and affiliations when known (as well as authors listed in the program but not present), but if there any corrections that need to be made, please let me know.
Jump to:
Conference Day 1
Conference Day 2
Conference Day 3
Conference Day 4
DHA Conference Day 1 (June 20, 2016)
The first day began with a free workshop on regular expressions by Aidan Wilson (@aidanbwilson) from Intersect. For those of us who were unfamiliar with this ‘search on steroids’, it was an interesting and very useful session. I was particularly glad that a Shakespeare play was used as one of the examples, since I have been thinking about Digital Humanities pedagogy in relation to literature courses for the past year or so and think there is potential here.
The conference opened with a Welcome to Country. Then the rest of the first day was a series of short Provocations focused on three main points (Professional Recognition, Research Infrastructure, and Redefining Digital Humanities) and presentations on e-research infrastructure and Gale Publishing.
Provocations session
Sydney Shep (Victoria University of Wellington) discussed some of the issues in New Zealand. At her university, student numbers are set to double by 2030, presenting both opportunities and challenges. Interdisciplinary work is not rewarded by the PBRF (Performance Based Research Fund) system. She suggested that instead of us being boundary riders in DH, we should be edge walkers and take advantage of our positioning in the system.
Simon Musgrave (Monash University) asked questions, including What is a reasonable process of validating work so people will take it seriously? What kind of peer review is needed (and how much time is it going to take)? Will I have to look at corpora of colleagues, for example?
Paul Turnbull (University of Tasmania) said he spends a lot of time writing letters of support for younger scholars, because he feels that we should lead by example by helping them out to obtain recognition. He addressed the critical need for defining and embedding digital literacy in the undergraduate curriculum, because it can’t wait. He also asked who should be driving big infrastructure projects: we as academics or big consortiums, or communities that need the projects and access. Who should ultimately be in charge? Are big infrastructure projects like Bamboo what’s best for the future of DH?
Christina Parolin (Australian Academy of the Humanities) said that we need to articulate what we need in order to transform our disciplines. Do we need a long-term strategy and plan for the sector? This could help prioritize investment and effort over a longer term period, address diversity of scale and sustainability, and address skills and capabilities needed for DH in the future. She said that we need to engage, advocate, and lobby, especially outside of the department. This includes institutions, state and regional governments, as well as international bodies (many postgraduate students in China are using Trove, for example – are their needs or potential funding pools being investigated?). Should there be a DH research infrastructure alliance?
Sarah Kenderdine (University of New South Wales) discussed Artificial Intelligence and its potential for DH. She mentioned that Google just opened its AI research institute (machine learning) in Zurich. Rembrandt’s paintings were put into machine learning and a robot painted something that seems very similar to a real Rembrandt painting. [NPR article on it]
Camellia Webb-Gannon (Western Sydney University) said that the humanities must attend to the coming apocalypse. She asked how can we in DH be addressing things such as environmental issues, discard studies (gadgets and e-waste sent overseas), and poverty studies. She quoted Tara McPherson and asked about racial violence and DH. She showed a Postcolonial DH cartoon by Adeline Koh about the new Digital Divide. It’s not that projects that take these issues into consideration aren’t already taking place, but maybe we should do more to mainstream them in our projects. Let’s use DH to pursue a just and inclusive humanities.
One response to the first part of the Provocations session was that we must also address training needs – many Humanities researchers are poorly trained in new methodologies. It was also said that it’s not just training, that it actually fundamentally changes how we practice the humanities. And if we don’t embed that in our undergraduate courses, we are missing out. [Yes!!] When it comes to better digital literacy, we’re part of making that happen.
eResearch Infrastructure session
Lyle Winton (Deputy Director, Research Platforms for NeCTAR [National eResearch Collaboration Tools and Resources Project]) discussed NeCTAR and its 12 virtual laboratories in Australia with over 10,000 users.
Sarah Nisbet (Marketing Manager for eRSA) discussed examples of infrastructure for humanities and social sciences.
Ingrid Mason (eResearch Analyst for Intersect) discussed how she acts as a translator to communicate the needs of humanities and social sciences to infrastructure builders. She’s written several case studies so far and sees a gap in the understanding of data needs and issues.
Deb Verhoeven (Project Director at Deakin University for HuNI [Humanities Networked Infrastructure]) offered questions like How can we remake the world from the perspective of the people who live in it (research infrastructure build from below, not top-down)? How can museum, for example, look at its collections from the perspective of the people? It’s not necessarily always about building infrastructure, but maybe about puncturing the infrastructure, being more critical. She noted that one of the challenges in the humanities is that we haven’t had experience in team-driven research and individuals’ research often gets lost or overlooked compared to other projects. We need the humanities to have a seat at the table when these decisions are being made about research infrastructure. She discussed the draft Humanities Research Infrastructure Alliance Statement which aims to be a kind of white paper that will discuss needs and issues and that can be shared with parties outside academia.
During the question/discussion period, Shep asked about what it means to rethink infrastructure across national boundaries. aaDH seeks to position itself in Australia, NZ, and the Pacific, but so far the emphasis has been on Australia. There was discussion around if something is funded by the Australian government, does that limit which researchers can access it? The answer was not necessarily because it is not currently a requirement to be Australian or doing research on Australia to access certain resources.
Verhoeven responded to a question about how it is good that libraries get rid of things eventually and make decisions (How do we think about data? What about sunsetting — getting rid of data because it costs money to store and things must be prioritized?). She said that researchers might think more about these things if they had taken a first-year History course or were more knowledgeable about these kind of issues.
Mason noted that the biggest problem in the last five years has not been technical issues but rather communication issues. Verhoeven agreed, saying that interoperability on the technical side is not the most problematic; it is often things like getting universities and other bodies to communicate. Some in the audience believed that collaboration should be a key component of eResearch infrastructure (issues when groups won’t use Google, for example, because of data concerns). Mason discussed liking the Zoom conferencing tool.
Verhoeven said that we talk a lot about making data accessible, etc., but we don’t talk about the researchability of the data very much. She also noted that she and Mike Jones wrote an article for the Conversation (“Treasure Trove: Why Defunding Trove Leaves Australia Poorer” and it got picked up by the Australian Labor Party and into their platform about Trove, so we should be doing more like this for impact in public eye. The session closed with discussion of payment for data storage – no one wants to pay for it, but we all need it.
Gale and the Digital Humanities – by Craig Pett (Research Collections Specialist from Gale, a part of Cengage Learning)
Pett gave an overview of Gale’s work, noting that its best known collections like ECCO and State Papers Online are only a fraction of the things it has digitized. He anticipated concerns over free access and said that although the ideal is that public organizations (like government) will fund all digitisation projects for historical documents and then everything will become freely available through our national institutions, the reality is that not all governments can or will do this. This is where Gale and other companies come in, fund the project, get it done, and get it out to the world. Otherwise, you could be waiting for 10, 50, forever years for digitization to be done. Gale sells the collections at the institutional level (like the library) so that the end user (student, academic) gets ‘free access’ at least. [Problem is that this means there is a barrier of needing to be associated with academia to do research. It is hard to be an independent researcher.] He discussed Gale’s word association tool which helps facilitate humanities research breakthroughs and discoveries.
Gale realizes that metadata may in fact be more important than the primary source data and is moving in that direction. For about 18 months, Gale has put metadata on a separate hard drive and offered that to institutions for research at no cost (sending hard drives to the institution rather than putting information online). He announced exciting news about an upcoming release wherein Gale will be uploading the last 17 years of millions of metadata onto a cloud server (called the Sandbox). GoogleBooks is also supposed to be adding their metadata to this resource. The goal is to have it ready to download and work with immediately. He said this should be completed fairly soon.
DHA Conference Day 2 (June 21, 2016)
Data Trouble – by Miriam Posner (UCLA Digital Humanities) (@miriamkp)
Posner began by asking: What troubles humanists about data? For instance, humanists tend to love to hate Google’s knowledge data project. But she is hoping to develop a shared vocabulary to help us be able to talk about some of these issues. She said that the constellation of terms that we now use for the disciplines of the humanities has not actually been around for all that long. Around WWII, the definition changed to become what we now know it to be today.
The Science article “Quantitative Analysis of Cuture Using Millions of Digitized Books” was by mathematicians, scientists, linguists, and they called it culturomics. The media loved this, but humanists reacted with “almost visceral distaste”. Humanists didn’t like it, trust it, or use it. This brought to light that it was not just what humanists studied, but how they studied it and the interpretations that were essential to humanistic study. We prioritize close reading – is this why we have avoided big data projects? We don’t seem to like doing the work with large datasets. We have an aversion to positivism.
Posner mentioned the article “Literature is not Data: Against Digital Humanities” by Stephen Marche on October 28, 2012, and said, That’s true. Nothing is data until it is structured and becomes useable. She gave the example of time: we experience time in different ways, but to deal with it, we have to be able to measure it. In another example, data may present certain items as seemingly of the same nature, like the “charge/conviction” items in the Digital Harlem Everyday Life 1915-1930 project. Data visualization necessarily leaves out certain data, but this is not obvious from the final product. A dataset looks naked to a humanities scholar – it leaves out the data that weren’t thought by anyone to be important (like the paper that the poster was printed on, the other text on the poster, how it was crumbled, etc.).
You may prefer the label woman or womyn, but we need to categorize to be able to count or query the data and then visualize it. We tend to collapse labels into one data category (like a census box checked ‘black’ when person identifies as ‘African American and Germa/multiracial) but this doesn’t work when trying to work with data. [But this doesn’t mean some of these categories can’t be contested.] It seems like scientists think that what we humanists do is to fill in gaps on a timeline and sharpen our understanding of existing categories. But this is not what we see ourselves doing. We like to question and break categories.

We also must be aware of the constructed nature of categories. For example, how Māori classify things is different from how Westerners would (like they might categorize something as being similar to a canoe but others wouldn’t).
Posner gave an interesting example of William S. Jevons’ logic piano. The keyboard represents a set of constraints, just like the piano keyboard also constrains how many sounds you can make. The musician then translates an infinite number of sounds into the tiny set of options they have in front of them. There is a sense of play involved that may be fruitful in how we as humanists think about data. Also, humanists don’t see replicability as something they should be concerned about. This could explain why librarians have been frustrated at getting humanists to deposit their data.
During the question time, Shep asked about how Posner is dealing with Joanna Drucker’s idea that the world is data, and that we can only study a small portion of it. Posner responded that she uses Drucker’s work in everything she does but finds this concept hard to explain to undergrads. Shep also asked about whether the keyboard metaphor is gendered and to think about differences in what work Māori men and women do. There was a brief discussion of issues of agency and empowerment.
The Digital Humanities in Three Dimensions – by Tim Hitchcock (University of Sussex) @TimHitchcock
Hitchcock challenged us to think beyond the one-dimensional text and embrace the benefits of 3-D. He said that as humanists, we’re not actually concerned with texts, but with the human experience. So then why are we so concerned with texts?
He discussed the history of how things that are sometimes taken for granted came to be. Geography departments in the U.S. were closed down in the early 1950s, deemed Marxist.
We think we are making our own decisions, but we are actually inheriting traditions from the Enlightenment and decisions made a long time ago. The Library of Congress digitized 18th century books through microfilm, and then these are what have become available through collections like ECCO. This is the origin of why some texts are available online and other texts like Arabic are not – because white male European culture was considered important and worth storing and saving. Basically, white male European culture dictates what is available online now; selection bias was driven by the role of microfilm. Then rich white people tend to make available the texts that humanists study (it’s a selective intellectual landscape). He referenced Verhoeven’s feminist speech at DH 2015 for men to ‘get off the stage’ and apologized for not doing so sooner, then asked, How do we move beyond that elite, Western knowledge, that privileges the male?
He then provided several examples of projects that are taking advantage of 3-D modelling to go beyond the text and look at other aspects of human experience. In another field, the Royal Veterinary College of London with its LIVE interface is using a model of a cow.
The Virtual St. Paul’s Cross Project is modelling noise and speech in a historic environment. This allows voices of the crowd and women’s voices to come through.
Oculus Rift and other new technologies are changing how we connect with historical evidence, whether that’s text or something more interesting. When you add in the oral, the haptic, etc., you get something that is beyond the white elitist history. History then becomes more than an explanation; it enables recovery of the voices of the rest of the people and is more democratic. The material world in digital allows us to follow the not-so-easy traces of those who didn’t leave scribbles on paper in the past few centuries. It leads to more inclusive history.
Founders & Survivors: Australian life courses in historical context 1803-1920 looks at the 73,000 men, women, and children who were transported to Tasmania. It helps us address the question: How do we create empathy across 200 years of silence?
Hitchcock discussed some of his experiences working on the Digital Panopticon: The Global Impact of London Punishments, 1780-1925 project. He discussed how putting a historic map overlay on Google Earth allows him to see where sunlight would hit on the streets and buildings of a certain time period. Looking at maps, pictures, and models helps create a sense of the positioning and space, including in something like a model of a courtroom. He also wants to create models of structures like houses and prisons to give people a sense of what it was like. What is it like when you walk into the dock? What was it like on a transport ship? What can space, place, and voices give us that we couldn’t get before? He believes that projects like this make the history ‘from below’ more accessible and more imaginable. It is in some ways a way around the conundrum of the limitations of the text and allows full emotional engagement with the people of the past.
Sites and Projects Mentioned: Virtual St. Paul’s Cross; Transcribe Bentham; Darwin Manuscripts Project; Jane Austen Fiction Manuscripts; The Newton Project; The Digital Panopticon
During questions, Verhoeven asked, How do we move forward as a community of scholars, given that we are proscribed by past judgments? Hitchcock responded that we are nowhere near a systemic analysis of big data or where we got the data. He said footnotes are rubbish – they don’t work anymore. We need to be able to show what we know and don’t know, the methodology, in a different way. He also mentioned that he is skeptical of ‘authentic music performances’ like of the early ballads, because a modern audience has no context or idea what the feeling was like in a street performance in the 1790s.
Using Ontologies to Tame Complexity in Spoken Corpora – by Simon Musgrave (Monash University) (@SimonMusgrave1) (also Haugh Michael, Andrea Schalley)
Musgrave discussed coding practices in research on spoken corpora. He said that people code for what they’re interested in, not just pragmatic categories. Interestingly, laughter can actually be transcribed in a high degree of detail. (Conversation analysis is a field of study in itself.) What kind of vocalic quality does laughter have? Volume, pitch, etc. What prompts us to use awkward laughter? He has used regular expressions to find examples in the data, like looking for instances of (laughs) in a transcript. One issue is that with different coding practices, data sets and results can be very different.
Shep asked, Are there pragmatics that can code for irony? Musgrave responded that it’s hard because the text doesn’t necessarily have the visual cues that we need to know irony (why people on social media have to signal *irony because otherwise a post lacks context). Someone asked about whether semantic analysis on emoticons could be used since there is already some community agreement with what they mean.
Consuming Complexity: Genealogy Websites and the Digital Archive – by Aoife O’Connor (University of Sheffield) (@Ordinary_Times)
O’Connor works full-time for Find My Past, a subscription-based website and is currently doing her PhD part-time. She has noticed that when governments fund digitization projects, they usually focus on celebrating national identity (see Ireland). Genealogy is the second most popular hobby after gardening in the U.S., the second most popular search (after pornography), and a billion dollar industry. Interestingly, censuses were considered miscellaneous documents and relatively unimportant at one time. But priorities change, and we don’t know what will be important for historians and people in the future. Someone asked a question about when genealogy websites would make it possible to search for place not just person, like for people interested in the history of their house, for example.
Analysing Reciprocity and Diversity in Contemporary Cinema using Big Data – by Deb Verhoeven (Deakin University) (@bestqualitycrab) (also Bronwyn Coate, Colin Arrowsmith, Stuart Palmer)
Verhoeven discussed how the project is looking at 300 million show times, 97,000 movies, 33,000 venues, and 48 countries. She said it’s only big data if it causes you to have an existential crisis. The case study was of The Hobbit movie screenings. In looking at a visualization of how the film appeared in theatres around the world, it haemorrhaged, didn’t move in a linear movement or travel in that way. But none of the data turned up something that the researchers didn’t already know. So they switched from looking at countries’ tendency to show films to looking up which countries had more equitable relationships with other countries, more reciprocity. That revealed potentially more interesting data to analyze further. Verhoeven mentioned The Arclight Guidebook to Media History and the Digital Humanities, which is an open access book.
What’s Going On Over There? Ventures into Digital Humanities at University of Wollongong Library – by Clare McKenzie (Manager, Scholarly Content) (@ccmcknz) and Kerry Ross (Manager, Archives) (@libinwonderland)
McKenzie discussed the University of Wollongong’s institution-wide shift in 2015 towards digital skills. A success case was the History program and Creative Arts program working together on a project to engage undergraduate students. The third-year students filled out a survey through SurveyMonkey about the portal that had been set up to help them with the project, and the responses were favorable. Ross then talked about how it is challenging to know whose realm things are in at a university. What is the library’s role? How can people cross traditional intellectual boundaries (library, academics, students, tools) with a DH project?

Going forward, they see the library as a partner rather than merely a service provider. This involves a project-based rather than service-based approach and learning on the fly to be able to build capacity for an agile response that is still sustainable. They invite collaborations for more of the library’s collections. They mentioned that they used Omeka because of its ease of use, and that it empowered a History academic to curate her material.
Research Environment for Ancient Documents READ Project – by Ian McCrabb (University of Sydney)
McCrabb discussed the Research Environment for Ancient Documents READ software and its potential for scholars of these kinds of texts.
Herding ElePHaTs: Coping with complex object biographies in Early English print – by Teri Nurmikko-Fuller (@tmtn) (also Pip Wilcox, Kevin R. Page)
Nurmikko-Fuller discussed the Early English Print in the HathiTrust, a sub project of the Mellon-funded Worksheet Creation for Scholarly Analysis WCSA project. Sometimes with birth and death dates, for example, all you can say is that you are certain there is ambiguity (know someone was active in 1850s, for example). The researchers created categories for ‘precisedate’ and ‘ambigdate’ [not exact terms], so even though they had to give a date for the ambiguous one, if you know the category is ambiguous, you know that they are not sure. Sometimes you just have to put a date to have some data to work with.
Deep Mapping & The Atlas of Maritime Buddhism – by Sarah Kenderdine (University of New South Wales)
The Atlas of Maritime Buddhism project aims to help rectify the dominance of Silk Road stories over other means of exchange, such as maritime trade and monks traveling. Its theoretical basis lies in carto-criticism (critiques the Cartesian map worldview). Kenderdine discussed how the Dunhuang Caves in the Gobi Desert in China (a World Heritage site) have been photographed and enabled the creation of an augmented reality version in a type of virtual cave [more about the process]. Visitors to the exhibit use handheld devices to hover over the walls and see what is in the real cave. These devices, she emphasized, are intuitive for both grandchildren and grandparents, and meant to be a social group experience and not everyone on their own devices. One quite interesting aspect was that they filmed dancers on green screen and superimposed them on the walls of the wall experience to simulate the four dances depicted.
Paper Miner: Towards Digital Conceptual History – by Paul Turnbull (University of Tasmania)
Turnbull noted the lack of collaboration and communication between information scientists and traditional humanists. He showed the project of Paper Miner, and how far they got before the money ran out, which seems to be a common issue with DH projects. They approached Google about getting their help with automating the finding of locations in the Trove newspaper data, but Google realized what they wanted to do and wanted to charge a lot of money for helping. Paper Miner is currently tied to Trove, but there is no reason why it can’t be linked to other datasets. The challenge is that the main driver of the project has since passed away and they are left with minimal documentation, so will probably have to build it all over again. Advice for other projects is to keep better records.
The Complexity of Commonplaces: Digging into Eighteenth Century Collections Online (ECCO) – by Glenn Roe (Australian National University) (@glennhroe) (also Clovis Gladstone, Robert Morrissey)
Roe noted that before the current information overload, there was the Early Modern information overload (see Ann M. Blair’s Too Much to Know: Managing Scholarly Information before the Modern Age). So we’ve actually been dealing with this problem since the printing press. The challenge with ECCO is that there are duplications of works (24 reeditions of Hamlet for example), dirty OCR, and a large dataset size (205,000 texts). The Commonplace Cultures project looks to find passages that were shared. The Bible also presents a challenge because there are so many common passages (so much so that they had to make a ‘Turn Bible off’ button). For a viral poem of its time, check out James Thomson’s “Spring” 1728. Roe said that they didn’t want a boring search function to come at the end of the project, but that’s what they ended up with. His passing comment about being able to look up famous figures like John Locke and Thomas Paine and see where they were referenced in EBBO and ECCO signalled potential pedagogical uses.
Ngrams Against Agnotology: Combatting Tobacco Industry Narratives About Addiction Through a Quantitative Analaysis of 14 Million Documents – by Stephan Risi (Stanford University)
Risi is a historian of tobacco and looks at Truth Tobacco Industry Documents (held at UCSF). Tobacco-analytics.org is the resource he wishes he had had when he started his studies on tobacco. People have known they were addicted for a long time (John Quincy Adams, for example). Agnotology is the study of (culturally-induced) ignorance (see Agnotology: The Making & Unmaking of Ignorance) edited by Robert N. Proctor and Londa Schiebinger). Risi looked at the term nicotine as well as the 75 words that surround it (in order to get a sense of the context), then looked at addicted, addiction, addict, addictive in that nicotine database; he found that it wasn’t until the late 1980s and 1990s that nicotine addiction was used as a term. Smoking habit, on the other hand, was used before then. Thus arises one of the limitations with Ngram searches, that terminology and phrases change over time. When neurology became popular, as opposed to psychology and study of different types of personalities that might be predisposed to smoke, there became more evidence that things like gum, the patch, and replacements could affect the brain and be used. These terms only started being used in late 1980s and 1990s. Ngram can help find these kinds of connections or rises and falls in history. One challenge is to try to determine what was only available to tobacco industry executives and what was available to the public in things like newspapers. [My question: what happens to all of the documents stored by corporations and organizations that are not forced via subpoena to make these things publicly available?]
DHA Conference Day 3 (June 22, 2016)
Serendipity & Palimpsests: Deep Time, Spatial History and Biographical Complexity – by Sydney Shep (Victoria University of Wellington) (@nzsydney)
Shep opened her keynote with what she called a ghost story and went on to discuss the Tuatara Beer brand in New Zealand and their use of an old-school, weathered, distressed font in advertising. Buildings that have their outside walls painted over (like for advertising) are one example of a palimpsest, defined as “something that has changed over time and shows evidence of that change” or “a very old document on which the original writing has been erased and replaced with new writing” (Merriam-Webster). Shep reminded us that animal skin was scraped and used to write new text or correct scribal errors, a type of medieval recycling. Urban signage, like that discussed with Tuatara, allows the study of geosemiotics, and place is incredibly important. It speaks volumes about history and erasure. Outdoor advertising provides a window into history.
Shep talked about the Serendip-o-matic.com tool and how it seems to show you your interests, but what if you don’t know what your interests are? Everything that it will find is already categorized in European terms and keywords that have been used in the collections it is searching. In discussing her Marsden grant work on biographies of Victorian people, she described how she ended up focusing on one man, William Colenso, and his entanglements. He’s a multifaceted biographical subject. How can biographers deal with such a polymathic personality?
She provided an interesting quote from Janet Brown’s (2009) “Making Darwin. Biography and the Changing Representations of Charles Darwin”: “Every generation of historians recasts the past.” She asked, Can there ever be biography? We make history in relation to what we want to figure out about our present. What if we recast Colenzo as my Colenzo, or your Colenzo?
She mentioned her work on The Colenso Project, Maurice Bennett’s Toast Art that originated in Wellington (where slice of white bread is the pixel unit), and Storycube & Biocube [there are printable teaching resources of these via Cube Creator]. The DigitalNZ Magic square (with help from Tim Sherrratt) can construct a biography out of various scraps from Colenso’s life, and can allow us to discover through serendipity things we didn’t think of about him. It creates a deep map that makes more complex the process of biography. Her goal is to create woodblocks and eventually sound (exhibit hopefully to be opening in November in Alexander Turnbull Library). She also wants to recreate the lost four years of Colenso’s life, and use the algorithms to do that. Often we only have one side of a correspondence, and historians already kind of make up what the other side is. This is a new way to do that.
Regarding academia, Shep says we can’t be afraid to make change if we want to push the boundaries of what scholarship is today and in the future. She submitted an electronic monograph as a key research output, and the Marsden grant provides curiosity-based funding for the humanities in New Zealand. Remix, reuse, and repurpose the past is a growing trend around the world (steampunk, for example). Interestingly, she purposefully didn’t study history in official channels because she didn’t want to have the love of history in historical fiction driven out [it is sad to think how many people would agree with some version of this; that they didn’t study a humanities subject because it would be boring or turn them away from loving it].
Enabling Evidence-Based Analysis and Implementation of Indigenous Housing Programs – by Jane Hunter (University of Queensland) (also Tung-kai Shyy, Carroll Go-sam, Mark Moran, Paul Memmott)
Hunter discussed her social science work on Indigenous housing programs, starting by saying that it is widely acknowledged that Aboriginal housing is inferior. The project’s goal is to use the most relevant and reliable datasets to then make a web portal and do analysis on the data to have a better picture of how many people are living in the housing (they might lie for official surveys, for example), quality, needs, etc. One challenge is that it is hard to reuse anonymized and non-geolocated data to get a good sense of Australian housing issues. The Midja Integrated Knowledge Base provides statistical and geographical data for researchers (not open access because of some sensitive data). Data shows that Indigenous Business Australia is giving loans to high and middle income earners and areas with only modest needs, while ignoring areas that have good potential to get loans. For example, an area like Moreton Bay is receiving lots of loans but other better positioned areas are not getting any or very few. She mentioned that government documents have a lot of data in hard to access tables in PDFs and that she is interested in finding an automatic PDF Extractor Tool to extract tabular data out of PDF publications. [A person on Twitter @drjtwit recommended trying pdftables.com and said he helped write some parts of it.] During questions, Shep asked about helicopter research issues, as in what responsibility does a DH researcher have when they bring Western-created tools to Aboriginal or Indigenous communities and then leave. Hunter responded that other members on her team are Aboriginal or highly respected in the Aboriginal communities around Australia. Several members go out in the field and collect stories, so that is one way of not doing helicopter research.
Ecdosis: Historical Texts on the Web – by Desmond Schmidt (University of Queensland) (also Paul Eggert)
Schmidt described the reality that although libraries’ digital first policy means virtually no new printed material is being stored, they still have kilometers of rare books and manuscripts and few usable tools to edit and publish this material. Furthermore, the boom-bust cycle of DH projects makes it so that many DH projects don’t get to the stage where they are good enough for other people to work on it (making it open source doesn’t necessary mean that it will be picked up by other programmers). He asked, Is software really that fragile? Programs from 1970s still work perfectly. It doesn’t seem to be funding that kills projects like German TextEdit, but that they are too big and bulky. Software should be designed backwards from a user’s true needs (business document systems are not designed for historical materials, either). It is false to believe: ‘build it and they will come’. He went over waterfall versus agile development. Another issue is that if you ask people what they want, they’ll say: put a button over here, make that text red, but actually none of the software is really doing what they need. In their project, they found they had to start over, essentially, and an agile approach worked better. Ecdosis is not based on XML because of its issues with interoperability, reusability, etc. and it can be searched more accurately than XML, has a dramatic simplification of markup. Schmidt discussed the The Charles Harpur Critical fArchive where you can compare different versions of poems and it only takes a second. There are different colors for changed texts (red and blue, like Wikipedia). He also discussed the TILT test in Ecdosis.
Bridging complex heterogeneous datasets, workflows, and projects in Transforming Musicology – by Terhi Nurmikko-Fuller (The Software Sustainability Institute) (@tmtn) (and Kevin R. Page)
Nurmikko-Fuller discussed Transforming-musicology.org and the MuSAK (music annotation kit) where they put sensors on people to record their reactions during a live music performance (heartbeat, sweating) of Wagner’s Ring Cycle. They also had a musicologist live-annotate the score using a tablet and special pen.
Beyond the Sole Author? Measuring Co-Authorship Trends in English Literary Studies – by Elizabeth Leane (University of Tasmania) (also Lisa Fletcher, Saurabh Garg)
Leane gave an interesting overview of authorship in literary studies. Literary studies is the most heavily invested in the idea of authorship, and the idea of the sole author is pretty much standard and entrenched. We as scholars are surprisingly unreflective about our own academic authorship practices. Literary studies scholars collaborate less than any others (“Coauthorship of journal articles and book chapters in the social sciences and humanities (2000–2010)” by Ossenblock, Verleysen and Engels; Stylish Academic Writing by Helen Sword). Why? How might the rise of DH affect this model? What are the implications of a change? Project looked at MLA data as data source. The 4% coauthorship rate began to increase in 2005, but this is usually due to just two authors becoming more likely. There has been a 72% increase between 2000 and 2015 in co-authorship in literary studies. It remains a minority practice but is increasing. One challenge is that Digital Humanities as a keyword didn’t exist 20 years ago. Another issue to consider going forward is the convention regarding author order – now it is usually alphabetical but this could become difficult in lead-author projects. We need to deal with this issue in the discipline. Also, if the system favors people who co-author (now, that is sciences), what does that mean for the discipline?
Time for a Cultural Shift: Academia and Wikipedia – by Kara Kennedy (University of Canterbury) (@DuneScholar)
[This was my own presentation, so I will give a summary of it and some of the questions.] I discussed the why, the how, and the what a shift in academic culture regarding Wikipedia would look like. I believe Wikipedia embodies Digital Humanities values like open access and that DH scholars should be leading the way in engaging with it. I gave a brief history of the site, problems with a lack of diversity among editors (only around 10% are women), why those in academia are better positioned to make quality contributions, and the fact that the altmetrics donut now gives 3 points for a Wikipedia reference.

I advocated for academics to make contributing part of their practice and teach their students to contribute (valuable for digital literacy). I noted that the face of DH to the wider world (the Digital Humanities Wikipedia page) receives over 5,000 pageviews a month and yet is a relatively short article with a C grade. I ended with a challenge for us to work together to raise this page to featured article status. My parting line was: “Because when it comes to Wikipedia and academia, abstinence just isn’t working.”
As often happens in discussions of Wikipedia, people have strong feelings on the topic. During questions, Turnbull expressed his frustration over interactions on the site in his area of expertise, where seemingly amateur or uninformed editors challenge scholarly content and either delete or replace it with their own. Barnett voiced a concern that I have heard others make, that sometimes you have to take a break from it because of hostility and edit wars (and there are known issues like this with a gender component currently being researched). One of my responses is that having more academics involved would help make it so one scholar is not alone in these kinds of battles, especially when it comes to sensitive, politically-charged issues. Someone else said they had success in appealing to an admin about an edit and enjoyed making a contribution. Webb-Gannon asked how one would go about referencing themselves and if it amounts to a kind of self-promotion (there is a conflict of interest policy and you would generally add a note or reference in the references or bibliography section).
Thinking through Metadata – by Tully Barnett (Flinders University) (@tully_barnett)
Barnett discussed metadata and said that it is seeping into cultural communicative processes. She talked about Metadata Games and asked, Do the benefits of metadata outweigh the negatives? One issue is that when terminology changes, using new metadata can erase the previous terms.
MedievalTexts.com: Taking Medieval Textual Translation to the Masses – by Derek Whaley (University of Canterbury) (@whaleyland)
Whaley discussed the poor quality of digitized transcriptions of medieval manuscripts, and how he created a MediaWiki site (MedievalTexts.com) to enable crowd-sourced transcriptions and translations. The wiki format presents a low barrier to entry and allows people with a variety of skill levels to contribute – translations are only one aspect of the site. Currently, many scholars end up doing this work for their projects, but it is never published (translations often not considered as important as other research output). The main pages are the document source page and the transcription/translation page.

The site makes medieval texts more easily found, since they are Google indexed, and can be used as a teaching resource as well.
Donating Digital Me: What Can Be Learned from My Digital Footprint? – by Katie Hannan (Australian Catholic University)
Hannan talked about the serious implications of digital data after death. There is currently no way to donate our data or metadata. So what happens to all of the data from our devices, iPhones, iPads, etc.? She interviewed 99 people on what they thought about personal data donation. Gmail, Facebook, and YouTube were the highest used services that people were concerned about regarding personal information being on there (after they pass). She brought up the issue of whether or not families should be able to know if their loved one’s body contributed to a scientific breakthrough (if it were donated to science). Then her academia part-joke, part-maybe-this-could-actually-happen went over well: Would it be considered a non-traditional research output if a scholar donated their body to science and it was used in research, and should that go in the university’s institutional repository? *audience laughter* Someone asked about Eterni.me, a service that sorts through a deceased person’s social media accounts to create an avatar of them.
Aligning Digital Humanities Datasets for Unified Access – by Terhi Nurmikko-Fuller (The Software Sustainability Institute) (@tmtn) (also David M. Weigl, Kevin R. Page)
Nurmikko-Fuller discussed some of the technical background on current projects (lots of acronyms, like SALT).
Fison’s Problem with Australian Aboriginal Kinship Terms: Many to one mapping of terms to meanings and how the AustKin database can help – by Patrick McConvell (Australian National University, Western Sydney University) (also Rachel Hendery)
McConvell discussed the AustKin Project, a database showing kinship and social category terminology for Aboriginal Australia. He talked about Online Digital Sources and Annotation System (ODSAS) and issues with marking up text with TEI.

He also mentioned the display of data online like in the Spencer & Gillen project. It was interesting to hear about the history of how kinship terms were originally obtained. At first a 200-question questionnaire was sent around; after this didn’t really work, then Westerners actually went to the communities and saw the genealogies drawn using sticks in the sand. Kinship terms were different than Westerner missionaries thought and also changed over time with life cycles and life stages.
Closed Access – by Tim Sherratt (University of Canberra) (@wragge)
Sherratt discussed the concepts of open and closed access, especially in relation to government documents. The idea that the public had a right of access to public records did not go uncontested, especially in the Cold War 1950s. In Australia, the closed period of commonwealth access to public records is 20 years under the Archives Act (when the Act was first passed in 1983, it was a 30-year period but was changed in 2010 to be a 20-year period). He explained that it was important to first cover a ‘potted history’ of Australian Archival History because it informs what we do. He has created a Closed Access tool to allow you to see why things are closed access. You can drill down to a list of the closed files. But since you can’t then open them, this could be one of the most frustrating searches ever! However, you can request that something be opened up by submitting a request form for reevaluation of the file. Why are files closed? National security and individual privacy are top two reasons. Files are presumed to be closed if no decision is made after a certain deadline. We’re not blaming the archives—we know people are busy—but saying that we need to be having these conversations about what gets closed, why, etc. (there could be benefits to things moving at a snail’s pace because terms might change or governments might become more liberal, but those are not guaranteed).
Drifter: Approaches to Landscape through Digital Heritage – by Mitchell Whitelaw (Australian National University) @mtchl
Whitelaw gave one of the most unique presentations, during which the audience was able to listen to recordings of frogs inhabiting a river basin, which filled the lecture theatre with the sounds of nature. He discussed John Thackara’s Bioregions: Notes on a Design Agenda (2015) and its definition of a bio-shed, that we live among watersheds, not just in cities, towns, etc. He also talked about Timothy Morton’s “Zero Landscapes in the Time of Hyperobjects” and hyper objects (like global warming, styrofoam) that are all around us. We can’t see hyper objects, but computers can help see them for us. Whitelaw brought up Bruno Latour’s “A Cautious Prometheus? A Few Steps Toward a Philosophy of Design” (2008) and asked, Where are the visualization tools for the matters of concern? Then he showed us the Drifter project site which has a map showing information while playing frog recordings that have been geolocated in various river basins. There were more interesting aspects of other parts of the website too. He closed by asking if a mashup like this could be a representational strategy for matters of concern. [Slides available]
DHA Conference Day 4 (June 23, 2016)
Digital Knowledge in the Humanities & Social Sciences – by Paul Arthur (Western Sydney University) (@pwlarthur)
Arthur provided an overview of the changes that technology has wrought in the humanities and social sciences sector, as well as a brief look at where aaDH fits into that progression. He said that particularly in this DH community we can see the changes that technology has had in our lives and our research. Regarding the Internet of Things: by 2020, there are expected to be 50 billion intelligent devices on the network participating in the global data fest and communicating with each other. It’s interesting how this world has been taken in by humans as normal and routine, though it is similar to “A shattering of tradition” that the printing press brought about. The grand narrative of state-sponsored stories and information has given way to people being able to access all kinds of information on the Internet.
Therefore, the definition of writing now needs to incorporate activities like tweeting and texting as well as traditional book-length projects. The specialist computing power that was available in the 20th century is now within easy reach of many researchers and even the general public here in the second decade of the 21st century. Raw computing power is literally in our hands, rather than in a huge room, and it is not for just secrecy anymore (networks started with defense projects).
Post-structuralist theory (Roland Barthes’ 1975 Pleasure of the Text, Foucault) seemed to anticipate the dispersed network and questioning of subjectivity. Social media has led to many-to-many networking rather than one-to-one or one-to-many networking kind of communication. Web 2.0 has helped to tighten the Digital Divide by being more accessible to lower-income people. LinkedIn was just sold to Microsoft for $26 billion; it is hard to believe how social media networks grew that fast and became so valuable.
We are now conditioned to celebrate connectivity. We check how many followers, likes, etc. Obama became the first U.S. president to tweet out news/announcements before traditional means of sharing. Mass surveillance has now become standard. Who gathers data and what they do with it are now questions but there is no clear answer. There is tension between open data and privacy protection. Now it is virtually impossible to sign up for a service without giving away the right to not be tracked and have that data used for unknown purposes. Time magazine called ‘you’ the person of the year in 2006, signalling that we were in charge of our online lives. But this is no longer the case. We are not in control of our data.
Arthur then turned to discussion of academia in particular. He discussed the tension between crowdsourced knowledge production with its open access (Wikipedia model) and traditional specialized, academic knowledge production in limited distribution. Twitter is another example of a different kind of knowledge production that can easily reach millions. Two decades later we haven’t made a huge difference in the mainstream presentation of our humanities material (e-books for example). He said that Paul Turnbull’s South Seas online was influential to him in terms of showing what you could do with materials and how you could present them. He asked, How can we capture our humanities knowledge in new ways with unlimited potential? (This includes using components like GIS frameworks.) He noted that HuNI (Humanities Networked Infrastructure) is innovative not only for technical development but as an example of collaboration (hard-won). The thirty datasets aggregated on HuNI all have their own policies and restrictions on data sharing. But it’s a success of collaboration AND a research tool.
He said that energy in this part of the world is ramping up for Digital Humanities, so it’s an exciting time. We need new ways to recognize and evaluate the DH work we do. He mentioned the DOME Lab at Western Sydney University, the 2002 Australian e-Humanities Gateway, and the eResearch Australasia Conference 2016. Interestingly, the category of DH was not reported on in the October 2014 report entitled Mapping the Humanities, Arts and Social Sciences in Australia, perhaps because it spans disciplines (computer science, health sciences, humanities, creative arts). The Australasian Association for Digital Humanities (aaDH) was established in 2011, and the first conference was in 2012 in Canberra. aaDH has an MOU and organizes joint events with the Australasian Consortium of Humanities Research Centres (ACHRC) as well as with the Council for the Humanities, Arts and Social Sciences (CHASS).
Arthur closed by saying that analysis of data often provides only a starting point for ideas, rather than solutions or answers. We have a remarkable chance to participate in new methods and new modes of publication, and we should remember that digital citizens and digital literacy are important. During questions, Shep asked about what our moral responsibility is when we feed the machine by in a way celebrating all of this push toward more data. Arthur responded that there are movements seeking to address some of these issues, including the low-tech movement and Postcolonial DH.
AARNet GLAM Panel: How do we leverage research infrastructure to build data bridges between GLAMs and DH researchers in universities?
The four panelists were sponsored by AARNet (@AARNet) and included:
- Ely Wallis (Museum Victoria) (@elyw)
- Janet Carding (Tasmanian Museum and Art Gallery) (@janetcarding)
- Richard Neville (State Library of NSW) (@RNevilleSLNSW)
- Mary Louise-Ayers (National Library of Australia) (@MarieLAyres)
Louise-Ayers raised the issue of funding for Trove early on. She said that academics have a big problem looming that they might not be aware of. So far Trove content has been jointly funded, but only one-half of 1% is funded by universities even though academics are the ones who want to use it the most. The problem is that to get the whole corpus currently, it has to be downloaded onto a hard drive and soon they will have to start charging for it. There was 0% from research infrastructure funding to make Trove. The National Library can’t pay for it. How are researchers going to be able to access born-digital material in future when universities aren’t paying for the infrastructure?
Carding said that she thinks museums and galleries have been slower than libraries and archives to make data accessible. Also, funders haven’t necessarily been jumping on new ways of doing things, like big data. At the state level, they want to know what the benefits of digitizing things are. It should be conceived of as a citizen humanities project, and the goal should be to make a meaningful connection between people and their landscape and expressions through GLAM artifacts. She doesn’t think the solution for the next 20 to 50 years is being stuck in a room with a flatbed scanner! Someone asked about the Atlas of Living Australia, and it was not on Trove as far as she was aware.
Neville discussed how libraries’ systems are set up to capture bibliographic data, but now there is a lot of unstructured data being generated. The question is what to do with it? There is research potential to make projects around discoverability, because otherwise we are all scrambling around with massive collections that only have bibliographic data available to find. How to make it more accessible?
Wallis gave an example of how scientists in a funded project weren’t allowed to spend one cent of grant money on digitization, which caused a lot of uproar and forced them to use money to do other things.
The next questions directed at the panel were: How can GLAM & DH communities’ better leverage existing services provided and inform the development of new services? How can GLAM & DH practices be aligned so that GLAM data is quickly, appropriately and readily available to researchers using national research infrastructure services?
Neville found that students weren’t going to archives to look at real material anymore. So he started inviting students to see artifacts and manuscripts and experience the wonder of tangible objects. Libraries forget that people can’t read cards and abbreviations, and the average person can’t handle an API. How can libraries make data more accessible without using terminology or tools with specialist knowledge? Louise-Ayers noted that small-scale solutions (agile) are probably better than big infrastructure/committee when it comes to some of these issues.
Tim Hitchcock from the audience added that collaborative doctoral projects (comprising 10% now in the UK) between GLAM and DH are fruitful and establish lots of connections. Then it doesn’t become a zero-sum game of ‘who funds Trove’. Sydney Shep said that in her experience, the best research assistants are people who come out of information management, not computer scientists. They speak the language of the cultural heritage domain and the language of the subject specialist (English, History). They can translate. She mentioned summer scholarships with Digital NZ and internships. Mike Jones mentioned the McCoy project as an example of a joint venture working (it is between the University of Melbourne and Museum Victoria)
The next questions were: What advantages are there in alignment of the needs of GLAM & DH communities? Do we need to create data bridges for GLAM data to flow on and off Australia’s research data nodes for DH research? How do we build sustainable and scalable infrastructure for the long term to increase the capacity for Australian humanities researchers so they are able to search legacy archives and collections and sustain the value of data collections long term?
Wallis raised the challenge of data moving around and not taking with it information about copyright and licensing. An audience member noted that there is currently a license ref tag being developed to be able to attach to each object to address this issue. Louise-Ayers said that there’s a good list of references/licensing (Creative Commons, free-to-read) available now, but it’s hard to distribute this and explain it to the collecting institutions. There is just not enough funding for a roadshow to go around the country for two years to tell other GLAM institutions about their options. Wallis mentioned that a key challenge is how to make it so the next researcher doesn’t have to start from scratch.
Ingrid Mason read out the highlights of her notes compiled during the session, that it was about:
- reformatting relationships
- reconnecting those relationships and the processes that sit underneath them
- PhD programs
- how data is made accessible through licensing (progressing Open Access agenda when possible)
- forum opportunities
- how to collaborate effectively and join forces
- how to make feedback loop occur
- looking to NZ for their one knowledge network model (Digital NZ)
- making a citizen humanities topic for these communities (GLAM and DH) to explore together
As Luck Would Have it: Discovery in the Digital Age – by Deb Verhoeven (Deakin University) (@bestqualitycrab) (also Toby Burrows)
Verhoeven emphasized that making connections is no longer something that we can approach in a linear fashion – we need serendipity! She gave a few examples of serendipitous discoveries, including x-rays, pacemaker, LSD, microwave, superglue, and text messaging. Also, a fun fact is that Serendip was actually a place (Sri Lanka). Serendipity is renowned as a property of innovation. She uses Twitter for serendipity; she only goes on it for certain times of the day, so she is limited to who is online at that time or what bots are tweeting at that time. King’s College London even has a code of conduct for serendipitous research opportunities! The word serendipity has become increasingly popular. (But when she gave this talk in China, they didn’t have a word for it, so it is not a concept that translates everywhere.) Google is great at telling us what we already think we want to know. But it can’t really do much to make the serendipitous connections we might want in the humanities. She said that it’s not just about making connections to increase productivity, which is what governments are often interested in, and gave a quote from Jeanette Winterson to emphasize the point: “We didn’t build our bridges simply to avoid walking on water. Nothing so obvious.”
Music, Mobile Phones and Community Justice in Melanesia – by Camellia Webb-Gannon (Western Sydney University) (@camwebbgannon)
Webb-Gannon discussed how music production has changed to embrace mobile phones and allows for more expansive music communities. Wantokmusik.org will make an app to build a database (a Melanesian jukebox app). An additional benefit is that it will help address the overwhelmingly male domination in music production. She mentioned A Manifesto for Music Technology and that music was chosen especially because it is political.
Death and the Internet: Digital Legacies – by Craig Bellamy (@txtcraigbellamy) (also Bjorn Nansen, Michael Arnold, Martin Gibbs, Tamara Kohn)
Bellamy discussed some of the key issues with digital legacies: online memorials, property and privacy, and personal digital archives. The first online memorials appeared in the 1990s and were predominantly stand-alone webpages done by funeral directors. Then came Facebook. A user’s account is memorialized so that only confirmed friends can see the timeline, friends can leave posts in remembrance, and the system prevents anyone from logging into the account. It raises questions about what’s appropriate and who moderates the content (case study of Jill Meagher from Sydney, Australia). Regarding property, you need to think about: What do I actually own? Should I delete it? Or should I give it away? For example, with music you own physical copies of CDs but you don’t actually own online collections. The same goes for images and videos. Ebooks cannot be bequeathed like physical libraries. Email accounts are another issue to consider. However, mobile phone accounts are transferable, so their texts are recoverable (if worried about privacy, make sure to delete all your texts). The Google inactive account manager (or ‘death manager’) will send you an email every 6-12 months and will assume you’re dead if there is no response. Then it will carry out your wishes (including something like sending a list of your passwords to somebody you’ve chosen ahead of time).

You can create a digital register (which is a way of hacking non-transferability, because technically it is not legal to share your password, for example). How these issues are currently being handled do not include repurposing or remixing. The problem is the account: that’s what’s not transferable. It’s fine if you give someone your hard drive with your images, videos, etc.
What We Talk About When We Talk About Things – by Mike Jones (University of Melbourne; Museum Victoria)
Jones discussed challenges with data and information, especially in relation to search. For example, a Trove search is not as detailed as what’s available in Museum Victoria, but people might not realize there is more data on the home institution’s site. Even still, there is data that is not linked through a typical search box search on Museum Victoria. The challenge is how to show relationships and connections between things, rather than just keywords and data about the one thing. Things aren’t isolated blocks of information. Rather than a one-way flow, we might have a cycle of information that flows back on itself, especially in the GLAM sector. That way, you don’t have to look up a piece of information about, say, an explorer’s notebooks every time you look him up, especially when that information is already available at other institutions. The search box is too limited and often requires you to know the connections already.
Tending the Archive – by Louise Curham (University of Canberra)
Curham provided an examination of performance and pedagogy in the Expanded Cinema re-enactments being done by Teaching and Learning Cinema. The performance-dependent object is the connection between analog and digital. To access this material in a way you can understand relies on your experience. The project is looking at 1960s and 1970s performances. Embodiment is at the front, and it changes the paradigm. It’s about maintaining and invigorating the performances (a kind of reuse).
Evaluating Ontologies in the Context of Ancient Sumerian Literature – by Terhi Nurmikko-Fuller (The Software Sustainability Institute) (@tmtn)
Nurmikko-Fuller reviewed several aspects of a DH project involving Ancient Sumarian literature, noting that there is much richness in the literary corpora of the ancient Near East and so much potential. She mentioned the Electronic Text Corpus of Sumerian Literature (ETCSL), Cuneiform Digital Library Initiative (CDLI), and Open Richly Annotated Cuneiform Corpus (Oracc). She also discussed an ontology for cultural heritage data through the CIDOC Conceptual Reference Model (CRM); OntoMedia, which was used for capturing narrative in fiction [including science fiction]; and the Brat rapid annotation tool, which lets you mark up a text according to an ontology you have already uploaded.
Hidden Narratives: Inventing Universal History in Joseph Priestley’s Charts of History and Biography – by Crystal Lee (MIT) (@crystaljjlee)
Lee began with a list of monarchs considered to be important (like Charlemagne) and then reviewed Joseph Priestley’s New Chart of History and Biography. She then gave the audience some questions to think about, including: How would you redraw this chart today? What assumptions or arguments are you making in your own data visualizations?
Visualising the Seven Years’ War: Testing Spatial-Temporal and Visual Analysis Methods for Postgraduate Historians – by David Taylor (University of Tasmania)
Taylor expressed some of the concerns that postgraduate students encounter when becoming involved with Digital Humanities projects, namely that students are still disconnected with the growth of Digital Humanities and often lack training.

He referenced a recent article by Katrina Anderson et al (2016) on “Student Labour and Training in Digital Humanities”. Taylor said that digital tools can seem counterintuitive to those embedded in close reading practices and pedagogies (he referenced Franco Moretti, Shawna Ross, and Mahony & Pierazzo). He said that the benefit of using DH for him was that it made him ask questions in a different way as a postgraduate historian. He urged the audience to involve students more in their digital projects.
Enhancing Search for Complex Historical Texts – by Desmond Schmidt (University of Queensland)
Schmidt continued his critique of other digital projects and demonstrated how difficult it can be to search historical texts with the search functions on offer. What’s a digital scholarly edition? It originally meant a critical edition created by scholars; now it can mean new digital versions of something like Mary Shelley’s Frankenstein. The six challenges (or tests) he has found for search engines searching documents are:
- Can search engine find words split into parts?
- Can search engine find words broken over lines?
- Can search engine find deleted text?
- Can search engine find inline-variants in their correct context?
- Can search engine perform literal search?
- Can search engine highlight text found in the document?
The answer is often no, and it isn’t easy to find things in a digital scholarly edition beyond the basics. Thus in his assessment of search, search is pretty poor. His solution was to ensure all text is findable, and all text that can be found is actually in the document. One challenge is to search many versions without duplicate matches. He looks at his Charles Harpur Critical Archive as an example of search working better. He wrote his own search engine [Classic DH! If you can’t find something that works, build your own].
Sonorising and Visualizing Archive Records – by Nick Thieberger (University of Melbourne) (also Rachel Hendery)
Thieberger discussed languages that are in danger of being lost and ways of visualizing or hearing them through various projects. The Worldmapper has maps where countries are distended by the number of languages in them. The Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC) collection contains unique records, sometimes the only recording of a language. He spoke about giving voice to the voiceless. There is work on augmented reality, like holding a device over a trigger that then plays something (a type of Harry Potter moment where the thing you’re looking at comes to life), and Virtual Reality headsets, where your gaze rests on a language and then activates the language being played. He acknowledged that these are cute visualizations, but are they research? Well, there is little online presence for many languages in the world and these projects can help us know our own content better. Museums are increasingly looking for indigenous language content. Speakers of these languages and their descendants will likely also be interested.
The Lex Method: Visually Analyzing Cohesion in Text – by Caroline McKinnon (University of Queensland) (@Caroline_McKin)
McKinnon discussed the tool she has built (Lex) which uses latent statistical analysis (LSA) to measure cohesion in the text and visualize it.
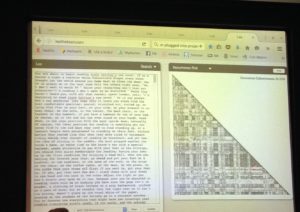
Each unit is a sentence. Her focus is on the process of editing, and she said that editing for coherence is very subjective and time consuming. We tend to work through a list of do’s and don’ts (like don’t have too many long sentences, etc.). But issues like incorrect grammar are actually not as problematic as a lack of cohesion. She found that there aren’t many computational tools to help with scholarly editing. Plus, following the do’s and don’ts to do something like shorten sentences isn’t the whole picture and can actually reduce cohesion. McKinnon is therefore aiming to improve on what’s on offer from her competitor. Referring back to Verhoeven’s statement, she said that if big data gives us existential crisis, maybe small data makes us go ‘hmm’ and be thoughtful on a smaller scale. She admitted that Lex is not an intuitive tool (the pyramid visualization is not easy to read), but not all visualization is designed to be easy to read nor give an instant result (if you attempt to use, it can take up to ten minutes to load, so be patient). Someone asked about Discursus and she said that her supervisor actually created that, so she is definitely aware of it.
Conference Closing
Paul Turnbull closed the conference by playing a digistory on Youtube called ‘For the Life of Him’ where historical documents are paired with a song to tell the story of a convict. Future conference ideas that came up over the course of the four days included holding it in New Zealand and having a Citizen Humanities theme.